基于云服務構建實時運營數據分析服務 數據處理服務篇
在基于云服務的實時運營數據分析體系中,數據處理服務是承上啟下的核心樞紐。它負責將原始、無序的運營數據,轉化為可供分析洞察的、結構化的高質量信息流。本文將深入探討數據處理服務的關鍵模塊、核心技術與最佳實踐。
一、 數據處理服務的關鍵模塊
數據處理服務并非單一組件,而是一個由多個協同模塊構成的復雜系統(tǒng)。
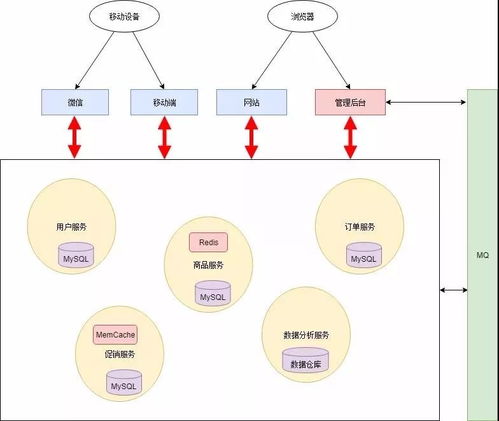
- 數據接入與緩沖層:作為數據處理的第一步,該層負責從各類源頭(如應用日志、數據庫CDC、IoT設備、API接口)實時或準實時地采集數據。云原生消息隊列(如AWS Kinesis Data Streams, Google Cloud Pub/Sub, Apache Kafka on Cloud)在此扮演核心角色,它們提供了高吞吐、低延遲、可持久化的數據緩沖能力,解耦了數據生產與消費,并能有效應對流量高峰。
- 實時流處理引擎:這是實時處理的“大腦”。它持續(xù)消費來自緩沖層的數據流,并執(zhí)行復雜的轉換、清洗、聚合與豐富化邏輯。主流云服務商均提供了托管的流處理服務,如Amazon Kinesis Data Analytics、Google Dataflow (基于Apache Beam)、Azure Stream Analytics。這些服務簡化了集群管理,支持使用SQL或高級編程語言(如Java、Python)定義處理邏輯,并內置了與云存儲、數據庫、分析服務的無縫連接器。
- 數據處理流水線編排:對于復雜的多步驟處理邏輯,需要一個編排框架來定義依賴關系、調度執(zhí)行并監(jiān)控狀態(tài)。云原生工作流引擎(如AWS Step Functions、Google Cloud Composer/Apache Airflow托管版、Azure Data Factory)可以將數據提取、轉換、加載(ETL)或更復雜的機器學習推理步驟,編排成一個可靠、可視化的自動化流水線。
二、 核心技術考量與設計原則
構建高效可靠的數據處理服務需遵循以下原則:
- 容錯性與Exactly-Once語義:在分布式流處理中,故障難以避免。處理引擎必須能夠從故障節(jié)點或網絡中斷中快速恢復,并確保每條數據被“恰好處理一次”,避免重復或丟失,這是保證分析結果準確性的基石。現代云流處理服務通常通過檢查點(Checkpointing)和狀態(tài)后端來支持此特性。
- 可擴展性與彈性:運營數據量可能隨時間劇烈波動。數據處理服務應能根據負載自動伸縮計算資源(如Kinesis Data Analytics的自動擴縮容),無需人工干預,從而在控制成本的同時保證處理性能。
- 數據處理邏輯的靈活性與易維護性:業(yè)務規(guī)則時常變化。設計上應將核心轉換邏輯(如過濾無效數據、標準化字段格式、關聯維表)模塊化、配置化,甚至支持動態(tài)更新(如Flink的Savepoint),以減少代碼變更和部署帶來的服務中斷。
- 安全與治理:所有數據傳輸與處理環(huán)節(jié)都需加密(SSL/TLS,靜態(tài)加密)。通過云服務的IAM(身份與訪問管理)嚴格控制對數據和處理作業(yè)的訪問權限。應建立數據血緣跟蹤,記錄數據的來源、轉換過程與去向,以滿足審計與合規(guī)要求。
三、 典型數據處理流程示例
以一個電商實時運營儀表盤為例,數據處理服務可能執(zhí)行如下流程:
- 原始事件接入:用戶點擊、加購、下單、支付等事件被SDK采集,實時發(fā)送至云消息隊列。
- 實時清洗與豐富:流處理作業(yè)消費這些事件,過濾掉測試流量或格式錯誤的記錄,并實時查詢云數據庫/緩存,將用戶ID關聯上用戶層級、地區(qū)等維度信息,將商品ID關聯上品類、價格等信息。
- 關鍵指標聚合:在滑動時間窗口(如過去5分鐘、1小時)內,實時計算關鍵指標,如:
- 各渠道的訪問UV/PV
- 實時成交額(GMV)與訂單量
- 熱門商品點擊/銷售排名
- 轉化漏斗各環(huán)節(jié)的用戶數
- 結果輸出:聚合后的結果被實時寫入下游系統(tǒng):
- 寫入云托管的時間序列數據庫(如Amazon Timestream, InfluxDB Cloud)或OLAP數據庫(如Google BigQuery, Azure Synapse),供BI工具和儀表盤快速查詢。
- 將異常事件(如短時間內支付失敗率激增)觸發(fā)警報,發(fā)送至通知系統(tǒng)。
- 將明細或聚合數據歸檔至云對象存儲(如Amazon S3),供后續(xù)批量回溯分析或模型訓練。
四、 云服務的優(yōu)勢與挑戰(zhàn)
優(yōu)勢:
敏捷與簡化運維:托管服務免去了基礎設施的搭建、擴縮容、打補丁等繁重工作,團隊可聚焦于業(yè)務邏輯。
豐富的集成生態(tài):與同云平臺上的數據源、存儲、分析工具天然集成,降低了連接與管理的復雜度。
* 按需付費的成本模型:通常按實際處理的數據量或計算資源消耗付費,初始投入低,適合業(yè)務試錯與快速迭代。
挑戰(zhàn)與應對:
供應商鎖定風險:深度使用某云的特有服務可能導致遷移成本高。可通過采用開源標準(如Kafka、Flink/Beam)的托管服務,或在架構上抽象出接口層來緩解。
復雜場景下的成本控制:實時處理持續(xù)運行,若設計不當可能產生高昂費用。需精細監(jiān)控資源利用率,優(yōu)化處理邏輯,合理設置自動伸縮策略,并利用云提供的成本管理工具進行分析。
###
數據處理服務是將原始運營數據轉化為實時業(yè)務價值的關鍵轉化器。借助云服務提供的強大、彈性和托管的流處理組件,企業(yè)能夠以更低的啟動成本和運維負擔,構建起高可靠、高性能的實時數據處理能力,為實時監(jiān)控、即時決策和智能化運營奠定堅實的數據基礎。成功的關鍵在于結合具體業(yè)務場景,合理選擇云服務組件,并遵循彈性、容錯、安全的設計原則,構建一個可持續(xù)演進的數據處理體系。
如若轉載,請注明出處:http://www.dzs1.cn/product/43.html
更新時間:2026-01-09 20:27:10